Simple and Affordable Automation Powered by Machine Vision
There is often a misconception that automation introduces large investments and requires radical changes to the business model. However, as we addressed in our previous blog post, today’s technological advancements make the process simple and affordable. In a nutshell, it’s about identifying the areas where workers are exposed to dangerous and repetitive tasks, automating these, and freeing humans to pursue jobs that give a sense of purpose.
According to the World Economic Forum, Artificial Intelligence (AI) will create 12 million more jobs than it displaces, increasing the global GDP by 26% within 2030. Moreover, they compare the current wave of AI technologies to the introduction of the internet. Like AI, the introduction of the internet brought about skepticism about job security. However, now we know that the internet has created millions of jobs.
Technology does not remove the need for human labor but changes the type of labor required. Are you ready to adapt to the coming changes?
This blog post builds on our previous, introducing the pipeline from capturing data to analyzing it to be used for automation applications, covering the following topics:
- How machines see the world and the benefits of depth perception.
- Aivero’s unique approach to data compression and streaming.
- Depth perception through cloud computing and training deep neural networks.
Introducing Machine Vision to Depth Perception
Knowing how machines acquire information is key to understanding how they learn, leading us to the field of computer vision—a stepping stone for machines’ visual perception. Computer vision is the field of AI that enables computers to derive meaning from visual input such as images and videos. Here, images are fed and broken down into networks for machine learning algorithms to identify patterns and eventually distinguish and categorize objects.
In brief, computer vision refers to capturing, processing, and analyzing visual information. Machine vision is a subcategory that applies computer vision to industrial applications.
Machine vision systems (MVS) consist of software and hardware that captures and processes images to provide automated robotic control, inspection, and monitoring. There are several methods to gather data in MVS, most commonly by using 2D cameras. However, there are several benefits to using 3D cameras:
The Benefits of Depth Perception
Using 3D cameras enables capturing of depth data to determine distances and manage space. Therefore, by introducing machines to 3D, they understand the environment better through higher precision measurements and calculations. Through this, machines become better decision-makers due to more nuanced information, increasing the reliability of total process output.
If you are interested in learning more about the differences in machine vision cameras used for automation, read this in-depth explanation about the benefits of using 3D vs. 2D cameras by Zivid, a high-quality manufacturer of 3D cameras based in Norway.
3D cameras capture images as depth maps; these are color maps where each depth pixel represents a color value that translates to distance. From depth maps, we compute point clouds by reversing the path of light traveling from the object to the camera’s sensor. The point cloud representation enables machines to observe geometric relationships and volumes, called depth perception.
The machine vision market is expected to grow at a CAGR of 7% by 2026
Markets and Markets report an increased demand for higher quality inspection and vision-guided robots to drive demand for machine vision solutions. 3D data adds to the quality level by providing more nuanced information. Depth perception allows machines to observe distances and relationships, enabling more precise actions. Although 3D data introduce several benefits it hasn’t always been practical to exploit:
Depth cameras typically output uncompressed raw color maps as sequential images in the range of 10 to 60 frames per second (FPS). A color map of full HD 16-bit depth map at 60 FPS would translate to a data rate of approximately 2 Gbps. A 1 hour recording of 2 Gbps equals around 1 TB of storage. It would be impractical to stream across networks due to latency, implying a strong incentive to compress the 3D data. As a result, Aivero developed the 3DQ framework.
Leveraging 3D Data in Machine Vision Applications
Processing, storing, and transmitting 3D data requires significant computing power, bandwidth, and storage capacity. However, it is possible to stream the data to locations with the necessary processing power when compressing it. Hence, compression opens several doorways to various machine vision applications to use 3D data. In addition, compression removes the need to invest in expensive hardware onsite:
Aivero’s 3DQ framework is a lossy compression algorithm that compresses 3D data by up to 20x while maintaining acceptable to near-lossless quality at high frame rates. The framework combines unique compression algorithms with off-the-shelf components to stream 3D data with high throughput and low latency. This way, compression enables data to be streamed and utilized across units and locations.
Compression shifts capital expenditures (CAPEX) to operational expenditures (OPEX) as cloud computing and 3DQ are offered as a service!
Aivero enables an off-the-shelf edge device to stream data to public cloud providers such as Amazon Web Services, Google Cloud, and Azure. These companies provide clusters of Central Processing Units (CPUs), Tensor Processing Units (TPUs), and Graphics Processing Units (GPUs) to meet the processing power required to train models. Meaning that instead of investing in the processing units yourself, a cloud provider leverages distributed networks to allow training applications to be faster, scalable, and flexible, on-demand!
Deep Learning in a Nutshell
In computer vision, tasks are automated by giving computers a higher-level understanding of digital images or videos. Here, deep learning is commonly used to imitate the data processing function of the human brain, using large amounts of data to train models. Deep learning architectures have two or more hidden layers in the neural network, which continually analyze data with minimal to zero human interference. As a result, such models enable computers to interpret visual input and apply interpretations to automate decision-making tasks.
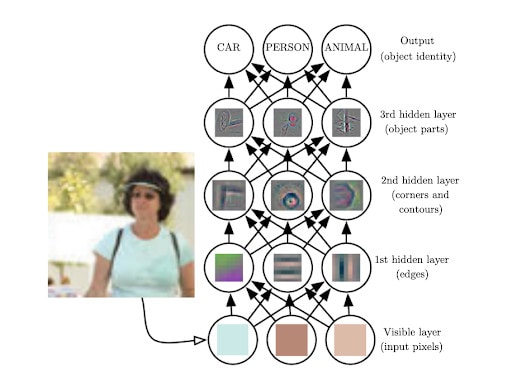
Neural network algorithms are multi-layered structures that try to replicate the behavior of biological neural systems. The base unit for artificial neural networks is the neuron. As in its biological counterpart, the artificial neuron is more effectively used within a network. It can receive a signal, process it, and propagate it to other neurons. At each connection, weights are applied to the input signal, passed through an activation function, and forwarded to the next neuron.
In convolutional neural networks (CNN), convolutions are applied when processing visual input, hence the name. Usually, a CNN works by running a filter across the input image, taking a patch of pixels and multiplying these with weights for each color value, extracting the most relevant features from the image condensing them into smaller representative matrices. Then, the values are passed forward through activation functions to extract higher-level features until reaching a fully connected classification layer. Finally, the classification layer outputs probabilities predicting the category of the image.
However, one must establish relations between the input signals, the network, and the desired output. The process that establishes that relation is called training.
Training a model consists of performing feedforward predictions using a network and adjusting the weights to minimize a predefined error function. Eventually, if everything works correctly, the network converges, giving increasingly smaller error, meaning that changes to the weights become finer-grained, based on the defined learning rate.
After validation and testing phases, the trained network can then be used for inference with new data.
Aivero’s Machine Vision task
In conclusion, the combination of 3D data, compression, and streaming help solve a variety of machine vision problems. For example, one of today’s major challenges in robotics is identifying objects to conduct path planning for tasks such as piece-picking and machine tending. When robots see the world in 3D, they can better understand how to handle objects because they observe relationships and dimensions.
Through deep learning, robots easily identify the correct action belonging to the respective objects, which means they don’t need to be reprogrammed each time tasks vary. Moreover, robots become more reliable because 3D data is less susceptible to environmental disturbances, such as changing light conditions.
Finally, 3D enables a closer depiction of how humans perceive objects. Thus, other applications such as inspection and monitoring are made with higher accuracy and quality. Essentially, a deeper understanding of the work environment requires depth perception; therefore, 3D matters as it enables automation to become simple and affordable.
Read more about Aivero’s solution and how robotics-as-a-service can automate your processes in a simple and affordable way!